My Thoughts On The GitHub Actions Runner Controller
Updates
- 2023-08-09 - Updated setup steps to utilize GitHub-supported resources. The mechanisms I was previously using are community-supported but are not officially supported by GitHub. Also thanks to @rajbos and @visualstuart for some editing help

The GitHub Actions Runner Controller (ARC) is a Kubernetes-based solution for hosting GitHub Actions Self-Hosted Runners within a containerized environment. It follows the Kubernetes Operator pattern, which essentially consists of a controller workload that monitors the Kubernetes cluster and manages a set of Kubernetes workloads based on Custom Resource Definitions (CRDs).
By using ARC, it becomes easier to:
- Deploy self-hosted runners on a Kubernetes cluster with a simple, repeatable set of commands
- Auto-scale runners based on demand
- Set up self-hosted runners across GitHub Offerings (including GitHub Enterprise and GitHub Enterprise Cloud)
- Direct workload jobs to utilize self-hosted runners by reducing the number of labels in
runs-oncriteria
tl;dr
This blog post is a bit long. There are a lot of details around GitHub ARC that I wanted to cover from setting up a very basic lab environment, enabling scaling, and some observations I’ve made while testing it out. Because of the length of this post, I’m going to lead off with my recommendations and conclusions.
When able, I would recommend using either GitHub-Hosted Runners or GitHub ARC because of their ability to scale to meet demands and because of their behavioral similarities. The way a VM-based runner works is different when compared to a GitHub-Hosted runner which can lead to inconsistencies in workload results. GitHub ARC is designed to closely mimic GitHub-Hosted runners in terms of their ephemeral nature, pre-loaded software (it’s not an exact match, but it’s closer than what you get with a self-hosted runner), and scalability (being able to scale from 0 and spin up and down runners on an as-needed basis).
The main times I would recommend against using GitHub ARC are when the infrastructure requirements are larger than what your Kubernetes cluster can provide, or if your enterprise will not allow outbound connectivity from the Kubernetes cluster to GitHub’s APIs. In those cases, I would recommend using VM-based runners. That being said, the networking requirements for GitHub ARC are the same as for a VM-based runner.
A high-level overview of how GitHub ARC Works

GitHub has a “How It Works” document published, but I wanted to summarize it here since understanding how ARC works is important.
ARC gets installed via Helm charts - including the supporting CRDs and controller workload. This controller monitors the Kubernetes cluster for any changes to AutoScalingRunnerSet CRD objects. Upon creating an AutoScalingRunnerSet the controller will call the GitHub APIs to fetch the runner group ID, and then it calls the GitHub API again to create a runner scale set in the GitHub Actions Service. It then will create an AutoScalingListener resource in the Kubernetes cluster which deploys a Runner ScaleSet Listener pod.
The Runner ScaleSet Listener pod uses a long poll HTTPS connection to the GitHub Actions Service and waits until it receives a Job Available message. The Job Available message is sent when a workflow run is triggered and the GitHub Actions Service dispatches job runs to Runners or Runner ScaleSets based on the value of the job’s runs-on property.
When the Runner ScaleSet Listener gets the Job Available message, it checks the corresponding EphemeralRunerSet configuration to determine if it can scale the number of Runners up to the desired count. If it can, it will acknowledge the message. The Runner ScaleSet Listener will then use a Kubernetes ServiceAccount to call the Kubernetes API to patch the corresponding EphemeralRunnerSet with the desired number of EphemeralRunners - EphemeralRunners are the pods that get scheduled to run jobs. The EphemeralRunnerSet will then attempt to create new runners (based on the updated configuration), and the new EphemeralRunners will request JIT configuration tokens from the GitHub Actions Service to register the new runners, and then schedule a new Runner pod. This JIT configuration token is requested based on a PAT token or a GitHub App, whichever mechanism was used for authentication during setup.
Once the new Runner pod is created, it uses the JIT configuration token to register itself with the GitHub Actions Service and then gets the necessary job details. Once the Runner has the necessary information to execute the job, it begins execution. Throughout execution, it will continuously send status messages and logs back to the GitHub Actions Service. When the Runner has completed execution, the EphemeralRunner controller will check with the GitHub Actions Service to determine if the Runner can be deleted. If so, the EphemeralRunnerSet will delete the Runner.
Setting up ARC
ARC is designed to run on a Kubernetes cluster. I’m going to host it on an Azure Kubernetes Service (AKS) cluster for testing purposes. If you don’t have a cluster that you can deploy into, it can also be deployed in a local environment running Minikube.
Installing the Controller and CRDs
The easiest method to install ARC is by using the Helm charts provided by GitHub.
NAMESPACE="arc-systems"
helm upgrade --install arc \
--namespace "${NAMESPACE}" \
--create-namespace \
oci://ghcr.io/actions/actions-runner-controller-charts/gha-runner-scale-set-controller
This will create a deployment named “arc” in a namespace named “arc-systems”, and also deploys all of the CRDs required to run GitHub ARC.
Setting up a Runner scale set
Now that the Controller is installed, it’s time to configure a Runner scale set. First, you’ll need to create a way to authenticate to the GitHub API. For my lab environment, I’m going to use a Personal Access Token (PAT). This will be stored in a Kubernetes Secret which will then be read by the ARC controller. This is a security best practice, and the alternative would be to set it in the Helm CLI when we install the gha-runner-scale-set helm chart.
NOTE: GitHub ARC supports PAT tokens or GitHub Apps. In an enterprise scenario, I would recommend using a GitHub App because it decouples authentication from a single user or account (as a bonus this also saves on the number of required licenses), centralizes access key management, and increases the API request rate allowed.
# Assumes that the `arc-runners` namespace exists already...
kubectl create secret generic gh-arc-runners-secret -n arc-runners --from-literal=github_token='<<PAT TOKEN GOES HERE>>'
Finally, we will deploy our runner scale set and pass in our Kubernetes secret we just created.
INSTALLATION_NAME="github-arc" #This is the value we need in the 'runs-on' in our workflows...
NAMESPACE="arc-runners" #The namespace to create the runner pods in
GITHUB_CONFIG_URL="https://github.com/molson504x/github-arc" #The URL of the repo, org, or enterprise that the runners will belong to
GITHUB_CONFIG_SECRET="gh-arc-runners-secret" #The secret we created containing our authentication info
helm install "${INSTALLATION_NAME}" \
--namespace "${NAMESPACE}" \
--create-namespace \
--set githubConfigUrl="${GITHUB_CONFIG_URL}" \
--set githubConfigSecret="${GITHUB_CONFIG_SECRET}" \
oci://ghcr.io/actions/actions-runner-controller-charts/gha-runner-scale-set
Once the Helm chart finishes running, you’ll see a new Runner scale set listed in the available Runners:
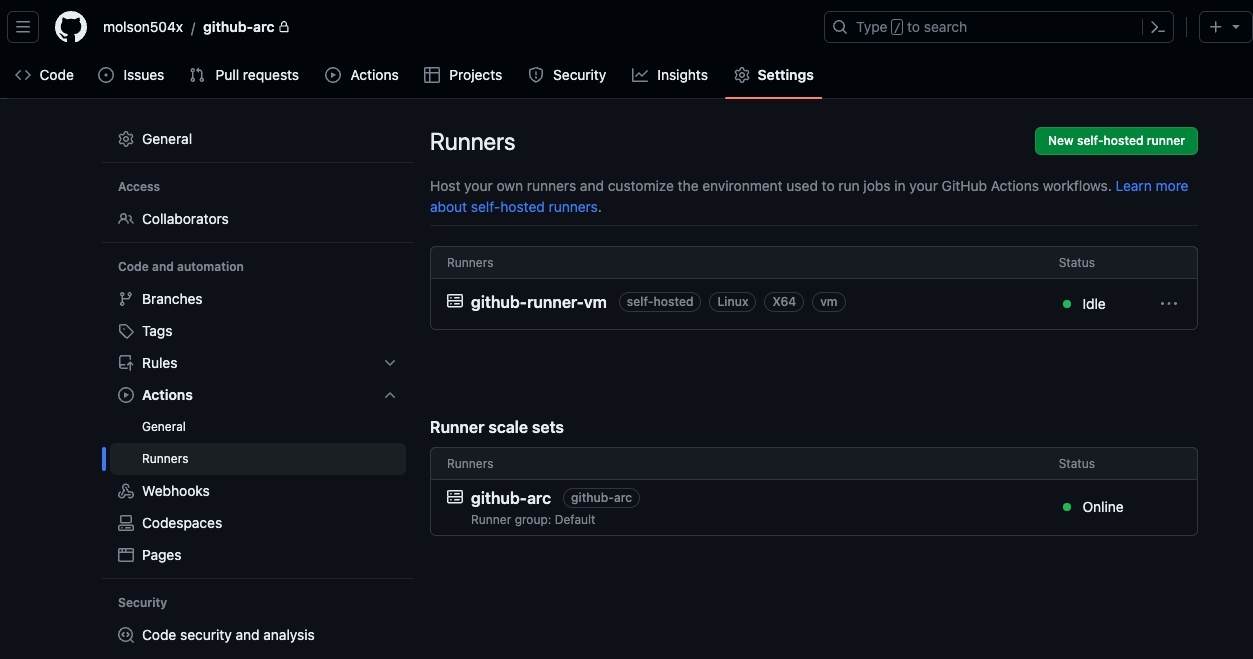
There are many more customizations available for the runner scale set, such as maxRunners and runnerGroup. These values can be found in the gha-runner-scale-set values.yaml file. For now, we’re going to use the default settings
Using The Self-Hosted Runner
Using a GitHub ARC runner is similar to using a GitHub-hosted runner - you need to pass the name of the runner scale set in your job’s runs-on clause. A runner scale set can have one or many labels. This differs from a VM-based self-hosted runner because the “self-hosted” label and “architecture” labels (“Linux”, “X64”, etc.) are not present. You cannot use labels to target runners created by ARC; you can only use the installation name of the runner scale set that was provided during installation.
# workflow information omitted
jobs:
Explore-GitHub-Actions:
runs-on: github-arc
steps:
# Job steps omitted
Differences I Noticed Between ARC and VM-Based Self-Hosted Runners
There are a couple of key differences I’ve found between the ARC runner and the VM-based runners:
-
GitHub ARC runners are ephemeral, whereas VM-based runners are usually not. This means that every time you run a new workflow using an ARC-based runner, you get a totally new runner instance. A VM-based runner does not have a totally clean environment every time a workflow run occurs. If you need proof of that, just navigate to the work folder (this defaults to
_work) and you can find the contents of whatever repository you ran a workflow against, along with a cache of every action that was used in that workflow. This sort of behavior is much different than what a GitHub-hosted runner provides - a GitHub-hosted runner always starts with a clean instance.This behavior can be observed by running a
lscommand against the working directory. Both the ARC-based runner and the VM-based runner will have a working directory created, but on the ARC-based runner that directory will be empty until acheckoutjob step is run or until something is written to that directory.ARC-Based Runner Logs
Run if [ -d "/home/runner/_work/github-arc/github-arc" ]; then if [ -d "/home/runner/_work/github-arc/github-arc" ]; then echo "Directory '/home/runner/_work/github-arc/github-arc' already exists." echo $(ls) else echo "Directory '/home/runner/_work/github-arc/github-arc' does not exist." fi shell: /usr/bin/bash -e {0} Directory '/home/runner/_work/github-arc/github-arc' already exists.However, we can see the non-ephemeral nature of a VM-Based runner if we run the same step (this was the 2nd run of the workflow):
VM-Based Runner Logs
Run if [ -d "/home/azureuser/actions-runner/_work/github-arc/github-arc" ]; then if [ -d "/home/azureuser/actions-runner/_work/github-arc/github-arc" ]; then echo "Directory '/home/azureuser/actions-runner/_work/github-arc/github-arc' already exists." echo $(ls) else echo "Directory '/home/azureuser/actions-runner/_work/github-arc/github-arc' does not exist." fi shell: /usr/bin/bash -e {0} Directory '/home/azureuser/actions-runner/_work/github-arc/github-arc' already exists. README.md -
Self-hosted runners allow you to manually install dependencies, whereas GitHub-hosted runners recommend running “setup” actions such as
setup-node,setup-dotnet, orsetup-go. This is because you don’t have access to the underlying infrastructure on a GitHub-hosted runner. GitHub ARC runners work similarly to the GitHub-hosted runners - their ephemeral nature means that each time a job is run the required dependencies will need to be installed. ARC-based runners do not have all of the pre-installed software that GitHub-Hosted runners have; the runner image definition can be found in the actions/runner repository.The recommendation is to use “setup” actions to install dependencies, or packages can be installed from
aptif a “setup” action does not exist. If neither of these is an option, you do have the option to create your own image. As a test, I set up a VM-based runner and an ARC-based runner and ran a simple workflow twice that installs Node 16. While it did not fail, there is a clear difference in the output logs:ARC-Based Runner Logs
Run actions/setup-node@v3 Attempting to download 16.x... Acquiring 16.20.1 - x64 from https://github.com/actions/node-versions/releases/download/16.20.1-5342959204/node-16.20.1-linux-x64.tar.gz Extracting ... /usr/bin/tar xz --strip 1 --warning=no-unknown-keyword -C /home/runner/_work/_temp/4080bd47-4321-4454-9c89-6fde3e80aa09 -f /home/runner/_work/_temp/d4fcb1a2-624a-4ddb-8a40-04bbbc7f5f10 Adding to the cache ... Environment details node: v16.20.1 npm: 8.19.4 yarn:VM-Based Runner Logs
Run actions/setup-node@v3 Found in cache @ /home/azureuser/actions-runner/_work/_tool/node/16.20.1/x64 Environment details node: v16.20.1 npm: 8.19.4 yarn:The VM-based runner cached the installation for installing Node 16, and it didn’t have to do it the 2nd time. This is due to the non-ephemeral nature of VM-based runners; the first time it ran the
setup-nodeaction it did install Node, but the second time it ran thesetup-nodeaction the action found that Node was already installed so it did nothing.
Conclusions
GitHub ARC is my recommended solution for hosting GitHub runners within a Kubernetes cluster due to its ability to automatically scale to meet demand and its behavioral match with GitHub-Hosted runners. The ability to automatically scale to meet demands eliminates the time and management overhead of deploying, configuring, and managing additional VMs as runners, and eliminates the additional configuration within GitHub that may need to be done to utilize the additional VMs. By being able to add and remove runners by automatically scheduling and unscheduling pods, deploying additional runners to meet demand is now fast and easy.
GitHub ARC also mimics the normal behavior of GitHub-hosted runners by being natively ephemeral and following the same patterns recommended for running actions on GitHub-hosted runners. This behavioral similarity leads to a consistent and predictable outcome when running actions against GitHub-Hosted runners and ARC-based runners.